增强对3D空间的理解能力能为AR带来更好的体验,例如苹果为其最新的iPhone 12系列加装了LiDAR,借助机器学习和iOS14的深度信息框架让机器理解人们周围的世界,从而为AR物体的精准放置提供了技术支撑,也为用户带来了更好的AR体验。 但目前来看,机器对人们周围3D环境的理解还停留在较为初级的阶段,而科技巨头们在这个领域的研究脚步也仍在继续。最近Facebook AI Research(FAIR)的一项研究就揭示了他们正在研究如果让AI更加智能地探索3D环境,并与之进行交互。
FAIR对3D环境及交互问题的探索在人类空间中运作的具身智能体(embodied agents)必须能够了解其身处的环境是如何工作的:该智能体可以使用哪些对象,以及如何使用它们?FAIR引入了一种增强型学习方法来进行交互探索,从而使一个具身智能体可以自动发现可供性(affordance)状况下新的未映射的3D环境(例如陌生的厨房)。 给定以自我为中心的RGB-D摄像头和高级操作空间,同时通过基于图像的可供性分割模型训练,该智能体将获得成功的互动。前者产生了在新环境中有效行动以准备下游交互任务的策略,而后者产生了卷积神经网络,该神经网络将图像区域映射到智能体,为它们的每个动作提供可能性,从而增强了探索的回报。 FAIR通过AI2-iTHOR(一个为可视化AI提供的交互式3D环境)展示了他们的想法。结果表明,智能体可以学习如何智能地适应新的居家环境,并做好准备,以迅速解决各种下游任务,例如“寻找一把刀并将其放在抽屉里”。
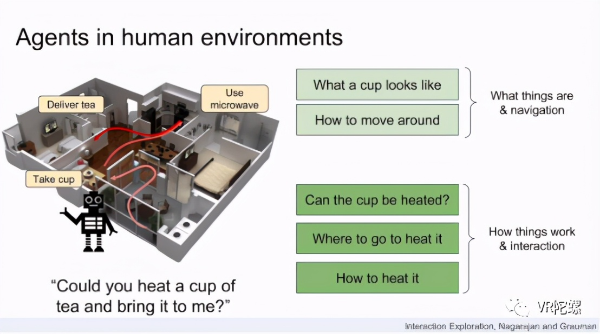
与环境交互的能力是在人类空间中工作的具身智能体的一项基本技能。交互使智能体能够修改其环境,从而使它们从语义导航任务(例如“去厨房;找到咖啡杯”)转移到涉及与周围环境交互的复杂任务(例如“加热咖啡并带来给我”)。 如今,典型的智能体通常都经过培训,可以在监督的方式下执行特定的互动。例如,智能体学会导航到指定的对象、灵巧的机器手学会解开魔方、机器人学会操纵绳索等等。在这些情况下以及其他许多情况下,无论是通过专家演示来表达,还是通过旨在激发期望行为来表达,需要先知道哪些对象与交互有关,以及交互的目的是什么。相比之下,FAIR设想了能够进入新颖的3D环境,四处走动遇到新对象并自动识别可供性范围的实现主体:什么是可交互对象,使用它们的相关操作以及这些交互将在何种条件下进行并且成功?然后,这样的智能体可以进入新的厨房,并准备好处理“在水槽中洗我的咖啡杯”之类的任务。这些功能将模仿人类通过学习到的视觉先验和探索性操作的结合来有效发现陌生物体的功能的能力。为此,FAIR介绍了对交互问题的探索:3D环境中的移动智能体必须自主发现可以与其进行物理交互的对象,以及与它们进行交互时有效的操作是什么。
如何识别3D环境并进行交互?
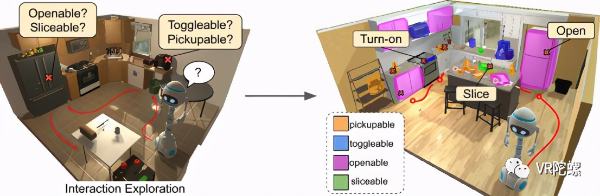
上图是这项技术的主要思想。FAIR训练智能体交互探索以快速发现可以使用哪些对象以及如何使用它们。在全新且看不见的环境中,他们的智能体可以推断其视觉可供性状况,并与存在的所有对象进行有效交互。最终的探索策略和可供性模型将智能体程序准备为涉及多个对象交互的下游任务。 探索交互对所有对象、动作、智能体位置和动作历史的乘积提出了具有挑战性的搜索问题。此外,许多物体被隐藏(例如,在抽屉中)需要被发现,并且它们的交互动力学不是直接的(例如,不能打开已经打开的门,如果拿起刀只能切一个苹果)。相反,用于在静态环境中导航探索的涉及相对较小动作的空间和动力学仅由障碍物的存在/不存在控制。 为了应对这些挑战,FAIR提出了一种深度强化学习(RL)方法,在这种方法中,智能体可以发现新的,未映射的3D环境的可供性能力情况,结果为在哪里进行探索以及尝试进行哪些交互提供了强有力的先决条件。具体来说,FAIR考虑一个智能体,该智能体配备了以自我为中心的RGB-D摄像头和一个由导航和操纵动作(左转,打开,切换等)组成的动作空间,其作用最初对于智能体是未知的。FAIR赋予智能体与环境中的所有对象快速交互的能力。同时,研究团队使用探索策略生成的部分观察到的交互数据,在线训练了一种可供性模型,以根据每个智能体的动作在此处成功的可能性来对图像进行分割。这两个模型协同工作以从功能上探索环境,参见图2。 FAIR用AI2-iTHOR进行的实验证明了相互作用探索的优势。他们的智能体可以快速寻找新对象,以在新环境中与之互动,从而使最佳探索方法的性能与所需时间步骤相比减少了42%,并且经过全面培训后,智能体的探索力得到增强,较之前增加了1.33倍的互动。此外,FAIR展示了他们的智能体和可供性模型有助于训练多步骤交互策略(例如,在水槽中清洗物体),在训练样本少且没有人为示范等情况下,在各种任务上的成功率提高了16%。
相关工作
视觉可供性
可供性是采取行动的潜力。在计算机视觉中,人们以各种形式探索了视觉可供性能力:从图像和视频中预测在哪里抓取物体,推断人们如何利用空间或工具,以及人体姿势的先验知识。FAIR的工作为学习视觉能力提供了新的视角。提议的智能体不是通过静态数据集被动地学习它们,而是通过与动态环境的探索性互动主动寻求新的能力。此外,与先前的工作不同,FAIR的方法不仅产生图像模型,而且产生探索相互作用的策略,FAIR证明了这种方法可以加速学习针对具体化主体的新下游任务。

探索3D环境中的导航
3D模拟器中最近体现的AI工作解决了导航问题:智能体在未映射但静态的环境中可以智能移动以达成目标。视觉导航的探索策略可以在无人监督的“预览”阶段有效地映射环境。该智能体因其推断的占用地图中所能覆盖的最大化区域、所访问状态的新颖性、推动探索区域的边界和相关指标而获得奖励。在VizDoom(常用增强学习实验环境)的游戏环境中,通过学习对智能体的健康状况带来影响的危险区域(例如,敌人,熔岩)的视觉外观,可以改进基于经典边界的探索。 与上述所有方法相反,FAIR研究在智能体可以修改环境状态(打开/关闭门,拾取对象等)的动态环境中进行交互探索的问题。他们的第二个最终目标不是建立自上而下的地图,而是在新环境中快速与尽可能多的对象进行交互。换句话说,对导航的探索能加快完成静态环境图理解,而对交互的探索能加快促进智能体完成对其在动态环境中交互的理解。
3D环境中的交互
除了导航之外,FAIR的这项研究还利用基于模拟交互的环境开发智能体,这些智能体还可以执行动作(例如,移动对象,打开门),最终将策略付诸实践。 FAIR的方法不是从演示中学习特定于任务的策略,而是从经验中学习与任务无关的探索行为,以快速发现可供性状况。正如他们在实验中所展示的,其模型可以与诸如上述任务的下游任务相结合,以加快智能体的训练速度。
自我监督的互动学习
FAIR分享通过互动学习的总体思想,其先前的工作研究是通过自我监督的训练来让智能体积极学习操纵策略的。非结构化游戏数据也已用于学习子目标策略,然后将其采样以解决复杂任务。对于桌面环境中的简单对象和网格世界中的区块推送任务,可以学习可供性模型。但是,FAIR更专注于需要导航和操纵(例如,移至柜台并捡起刀)的高层交互策略,而不是细粒度的操纵策略(例如,更改关节角度)。
内在动机
在没有外部奖励的情况下,强化学习智能体仍然可以集中精力满足内在动力。FAIR的研究基于好奇心、新颖性和授权来制定内在动机,以改善电子游戏智能体(例如VizDoom,Super Mario)或增加对象注意力。FAIR的想法可以看作是内在动机的一种独特形式,其中,智能体被驱使在环境中体验更多的互动。另外,FAIR专注于以人为中心的逼真3D环境而不是电子游戏,具有可以更改对象状态的高级交互功能,而不是低级的物理操作。
让环境理解和交互更智能FAIR的目标是训练互动探索智能体进入一个新的、看不见的环境,并成功地与存在的所有对象进行互动。这涉及识别可交互的对象、学习如何导航到它们,并发现如何与它们进行所有有效交互(例如,智能体发现可以拨动电灯开关,但不能拨动刀子)。
- 风靡全球的华为小米国产手机 在日本咋就干不过地头蛇?
- 双12手机怎么选?这几款5G旗舰值得入手 3399元起
- 苹果 macOS Big Sur 11.1 RC 预览版发布:增强支持 M1 Mac
- 习不习惯?老安卓用户用iPhone 12 Pro的十条感受
- 苹果华为OPPO手机视频卖点比拼,拍起视频谁更爽?
- 炫彩渐变夜光呈现 OPPO Reno5 Pro星河入梦版图赏
- 曝荣耀即将获售高通芯片,V40将于明年1月发布
- 轻薄影像之王来了!OPPO Reno5系列正式发布 这些卖点很赞
- 轻薄时尚办公影音全能跨界-宏碁传奇使用分享
- 六问AirPods Max
- 2021年国产最值得期待的3款旗舰手机,全部用上高通骁龙888芯片
- 凡尔赛本凡?库克谈用户沉迷苹果设备:设计过分让用户依赖的产品并非其初衷
- 盛惠102万元!三星110英寸Micro LED电视发布:99.99%屏占比
- 边云协同,汇聚生态,华为云使能千行百业智能升级
- 三星推出 110 英寸 4K MicroLED 电视:售价超 100 万人民币
- 中国供应商大胜:拿下苹果头戴耳机大部分订单,不过组装地为越南
- 魅族17+降噪耳机仅4399元起 黄章的这份暖冬套餐请查收
- 屏厂力作!三星推出110寸Micro LED电视,售价达102.5万元!
- 2020年最佳智能手机摄像头:华为 Mate 40 Pro
- “5G+人工智能”是啥样?让车更“聪明”,学校也有了“智慧大脑”
- 脑洞大开!三星申请无线充电戒指专利
- 苹果健身课Fitness+下周一上线,千亿规模的家庭健身市场,国外国内都怎么玩?
- Lava BE U参数现身谷歌网站 这款女性手机配置不高级
- AirPods Max悄然上架:复古外观+双H1芯片,4399值吗?
- 荣耀与高通或达成供应合作,V40 计划明年 1 月发布
- 苹果注视点渲染专利:提升AR/VR用户体验
- 聊聊华为GDE刚发布的一体化低门槛开发平台ADC 2.0
- 又一玩家杀入,谷歌首款自研芯片或将于明年问世,有意效仿苹果
- vivo X60系列或于12月28日发布 首发三星猎户座1080处理器
- 荣耀明确发展目标:成为国内第一!将获得高通芯片供应
- 「iPhone 12」貌似重大升级下的炒冷饭
- 这台神本治愈加班烦躁!轻松玩转N重任务,带你刷爆职场力
- 跟华为毫无关系的荣耀为何不值得买?
- 简单几步玩转手机桌面?教你轻松搞定OriginOS
- 取消耳机孔的 4 年后,苹果居然把耳机卖到了四千块
- 4399元的苹果新耳机AirPods Max,打扰了!
- 13天100万,Redmi开启爆款"收割机"
- vivo X60真机现身综艺,依然继承高颜值基因
- 今年配置性能最强的三款全面屏手机,高通865+苹果A14+麒麟9000
- 联想乐檬K12系列发布:6000mAh大电池,699元起
- 华为云亮相QCon2020深圳站,带你玩转云原生应用开发
- 【解决最大短板?苹果电池表带设计或将改善AppleWatch续航】
- “数字化生活”,等等老年人
- 三星也不送充电头了?快充产业或成最大赢家,关注这些产业链公司
- 《赛博朋克2077》即将开启,别怕!1060也可以一战
- iOS 14.3准正式版发布,更新了这些!
- 华为MateStation B515上架京东,售价4498元起
- 摩托罗拉G Stylus 2021全新渲染图曝光 颜值终于上来了
- 如期举办,华为花粉年会官宣
- 苹果再放隐私大招:明年起,未经同意跟踪用户的应用会被下架
- 来了!苹果圣诞节前夕发布AirPods Max耳罩式无线耳机
- AirPods Max售价离谱,全世界网友集体吐槽:像极了女性用品
- 性能全面升级的高通骁龙888,是计算摄影新时代的第一步
- 双12要来了!赶快把魅族17放进你的购物车吧
- 苹果的AirPods Max头戴式耳机卖4399元,真的是收“智商税”吗?
- 轻薄本市场值得深入细分,ThinkPad发布907g新品X1 Nano
- 谷歌Pixel 5 Pro外观首度曝光,屏下摄像头+高通骁龙865
- 三星 Galaxy S21 系列官方视频疑似外泄:只有 Ultra 采用曲面屏
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 直击华为首款商用台式机:商用PC的破局者来了